Kafka 快速入门
大数据:
- 如何收集数据
- 如何分析数据
- 离线分析
- 实时分析
消息收发模式:
- 点对点模式: 消息最多只能被一个消费者消费, 可以有多个消费者
- 发布订阅模式: 消费者可以订阅多个主题, 消费该主题中的所有消息
kafka是什么?事件流平台, 消息队列
大数据组件:
- 数据收集
- 数据存储
- 离线计算
- 流式实时计算
- 机器学习
事件流
以事件流的形式从数据库、传感器、移动设备、云服务和软件应用程序等事件源实时捕获数据的实践
Apache Kafka是一个事件流平台。
功能
- 发布/订阅事件流,写入/读取事件流,导入/导出数据
- 持久可靠地存储事件流
- 处理事件流
为什么要使用Kafka?
- 削峰填谷。应对瞬时突发流量
- 解耦。允许独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
- 异步通信,即允许把一个消息放入队列,但并不立即处理它们,然后再需要的时候才去处理它们。
工作原理简介
通过TCP协议进行通信的服务器和客户端组成。
是一个分布式系统。
服务器:以集群模式运行。
客户端:各种编程语言库。
实践案例
外卖系统
- 生产者:
- 订单微服务
- 消费者:
- 商家微服务
- 配送员微服务
核心概念
事件 event
记录了应用中“发生了一些事情”的事实。在文档中也称为记录(record)或消息(message)
事件具有键、值、时间戳和可选的元数据标头
代理 Broker
服务代理节点。Broker 是 Kafka 的服务节点,即 Kafka 的服务器。
生产者 Producer
发布事件,写入操作
消费者 Consumer
订阅事件,读取、处理操作
主题 Topic
主题类似于文件系统中的文件夹,事件是该文件夹中的文件。
分区 Partition
Topic是分区的,一个Topic可以有多个Partition
一个Topic分布在位于不同 Kafka Broker上的多个“桶”中。
一个 Topic 对应的多个 partition 分散存储到集群中的多个 broker 上
消息位移 Offset
Partition中每条message的位置信息,是一个单调递增且不变的值。
副本 Replica
分区副本。每个分区可配置多个副本实现高可用。
同一 Partition 的数据可以在多 Broker 上存在多个副本
每个 partition 选举一个 server 作为“leader”
主副本 leader
leader partition 负责读写
从副本 follower
follower 负责与 leader 同步数据
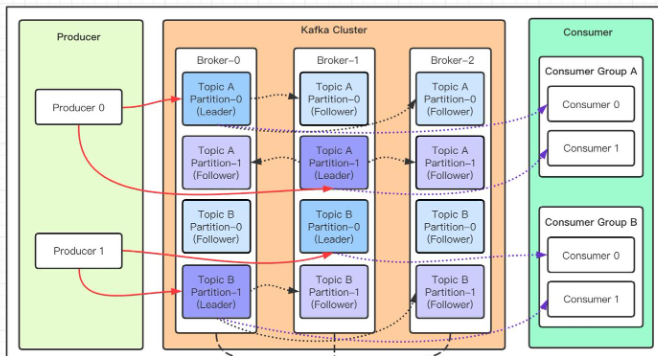
层级关系:
- Topic A
- Partition-0
- Leader (Broker-0)
- Follower (Broker-1)
- Follower (Broker-2)
- Partition-1
- Follower (Broker-0)
- Leader (Broker-1)
- Follower (Broker-2)
- Partition-0
- Topic B
- Partition-0
- Follower (Broker-0)
- Leader (Broker-1)
- Follower (Broker-2)
- Partition-1
- Leader (Broker-0)
- Follower (Broker-1)
- Follower (Broker-2)
- Partition-0
消费者组 Consumer Group
多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。
一个CG内, 一个Consumer可以对应多个Partition, 一个 partition只能对应一个consumer
消费者位移 Consumer Offset
表示消费者消费进度,每个消费者都有自己的消费者位移。
重平衡 rebalance
消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。
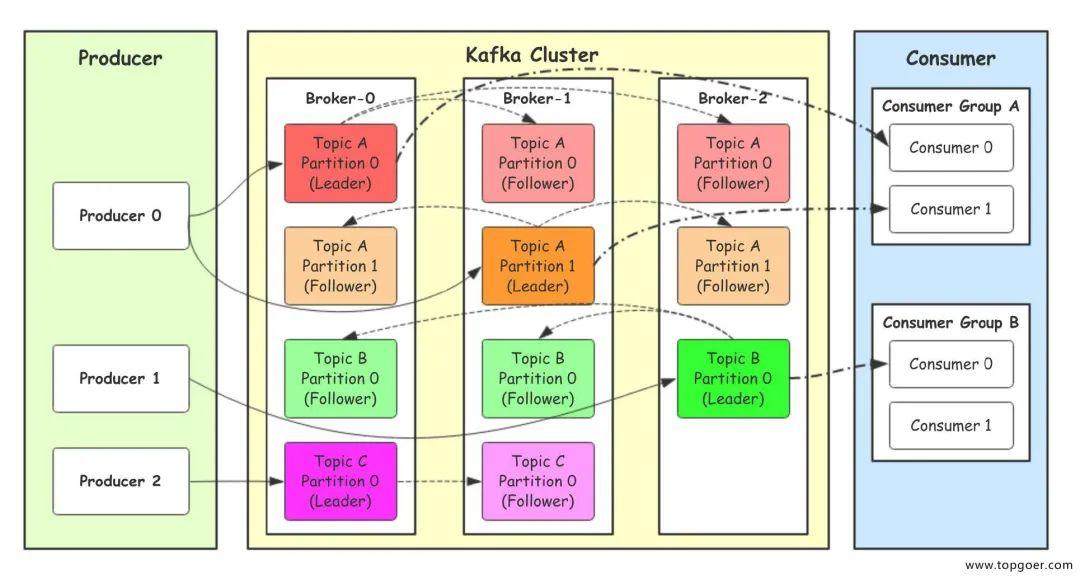
生产者发送数据:
- 参数 topic, partition, key, value
- 存在key, 根据key hash 选择 partition
- 不存在key, 轮询 选择 partition
- 批量发送
消费者消费数据:
- 以消费者组(Consumer Group)为单位, 订阅消息
- 点对点: 每个消费者的CG组都一样
- 广播: 每个消费者的CG组都不一样
- 同一个CG组的消费者不会同时消费同一个partition
- partition数 > 同一个CG组的消费者数: 会导致 某个consumer 消费2个partition
- partition数 < 同一个CG组的消费者数: 会导致 某个consumer 消费不到 partition
消息投递语义:
- Exactly Once: 有且仅有一次, 消息不丢失不重复, 且只消费一次
- At least once 最少一次, 消息不丢失, 可能重复
- At most once 最多一次, 消息不重复, 可能丢失
kafka集群核心组件:
- Broker 负责收发消息
- ZooKeeper, kafka4.0 已被KRaft取代, 负责故障转换, 主副切换
- Producer 负责发送消息
- Consumer 负责拉取消息
工作流程1: 发布/订阅消息的流程
- Producer 向topic 发送 消息
- Broker 存储该 topic 的消息, 分发到不同的partition
- consumer 订阅 topic, broker 向 consumer 提供 offset
- consumer 定期 pull 新消息
- broker 收到消息, 转发给consumer
- consumer 处理消息
- consumer 向 broker 发送消息确认
- broker 收到确认, 更新 offset 值
- 重复以上流程
工作流程2: 同CG组消费流程
- producer向topic发送消息
- broker 存储该topic的消息, 分发到不同的partition
- 消费者C1加入CG1订阅topic
- broker 以 发布订阅方式与 C1 交互
- 消费者C2加入CG2订阅topic, broker 切换为共享模式
- CG1订阅topic下的消费者数大于topic 的 partition 数, 新消费者将不会接受任何消息
zookeeper
- partition 的 leader选举
- 元数据存储
Kafka API
Admin API
用于管理
Producer API
用于将事件流发布(写入)到一个或多个 Kafka 主题。
Consumer API
用于订阅(读取)一个或多个主题并处理为其生成的事件流。
Streams API
用于实现流处理应用程序和微服务。提供了更高级别的函数来处理事件流
Connect API
用于构建和运行可重用的数据导入/导出连接器
应用场景
- 消息队列
- Kafka、ActiveMQ、RabbitMQ的对比
- 网站活动跟踪
- 指标监控
- 日志聚合
- 流处理
- 事件溯源
- 提交日志
快速入门
安装并配置Java
下载并解压
# 下载
wget https://downloads.apache.org/kafka/3.9.2/kafka_2.12-3.9.2.tgz
# 解压
tar -zxf kafka_2.12-3.9.2.tgz && cd kafka_2.12-3.9.2
# 启动 zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
# 修改kafka配置 config/server.properties
listeners=PLAINTEXT://0.0.0.0:9092
advertised.listeners=PLAINTEXT://本机IP:9092
# 启动 kafka
bin/kafka-server-start.sh config/server.properties方式一 zookeeper
启动zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties启动kafka
bin/kafka-server-start.sh config/server.properties方式二 kraft
生成集群 UUID
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"设置日志目录格式
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties启动Kafka服务器
bin/kafka-server-start.sh config/kraft/server.propertieszookeeper和kraft只能任选其一
创建主题 topic
bin/kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092查看topic
# 查看所有topic
bin/kafka-topics.sh --list --bootstrap-server localhost:9092
# 查看某个topic
bin/kafka-topics.sh --describe --topic quick-start-events
--bootstrap-server localhost:9092写入事件
bin/kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092
This is my first event
This is my second event获取事件
bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092
This is my first event
This is my second event资源推荐
- Apache Kafka 官方文档
- 【布客】kafka 中文翻译
- 四万字32图,Kafka知识体系保姆级教程宝典 - 知乎
- Kafka 中文文档 - ApacheCN
- kafka使用教程、快速上手_kafka教程-CSDN博客
- kafka 中文文档
- Kafka入门(一)
- Kafka 教程
- 三万字 Kafka 知识体系保姆级教程宝典
- Kafka
- kafka全解
- Kafka 简介
- Kafka详细教程(一)
- 学习 Kafka 入门知识看这一篇就够了!(万字长文)
图形化界面
https://github.com/lichengchuan/KafkaWebUIByLCC
书籍
- 《kafka权威指南》
- 《kafka技术内幕》
- 《kafka实战》
- 《kafka stream实战》
- 《Apache Kafka源码剖析》
- 《深入理解Kafka:核心设计与实践原理》
- 胡夕《Kafka实战》, 入门
- 朱忠华的《深入理解Kafka:核心设计与实践原理》, 进阶
- 郑奇煌的《Kafka技术内幕》, 高级
- 石臻臻的《石臻臻的杂货铺》, 实战
知识体系
基础
- Kafka 是什么? WHAT
- Kafka 解决了什么问题? WHY
- Kafka 怎么使用 ? HOW
重点
为什么 Kafka 吞吐量高?
为什么能做到“顺序写 + 零拷贝”?
核心
- 掌握Kafka的核心概念, 及其交互流程
概念
- Broker
- Topic
- Partition
- Producer
- Consumer
- Consumer Group
- Offset
重点
- Topic 为什么要分区?
- Consumer Group 如何实现负载均衡?
- Offset 是怎么管理的?
- Kafka 如何保证顺序性?
- Kafka 如何保证可靠性?生产端/消费端/broker端
- Kafka 如何避免重复消费?
- Kfaka 如何排查消息积压?
- 如何实现延迟消息?
- 如何处理消费失败?
架构原理
存储结构
- Log Segment
- Index 文件
- 顺序写磁盘
- Page Cache
高性能机制
- 零拷贝(Zero Copy)
- 批量发送(Batch)
- 压缩(Snappy / LZ4)
副本机制
- ISR(In-Sync Replica)
- Leader / Follower
- AR / ISR / OSR 区别
数据可靠性
怎样才能做到消费时, 既不丢失, 也不重复?
生产者可靠性
- ACK 机制(0 / 1 / -1)
- 重试机制
- 幂等性(Idempotent Producer)
- 事务消息(Exactly Once)
消费者可靠性
- 自动提交 vs 手动提交
- 重复消费问题
- 消费幂等设计
其他特性
- 事务(Exactly Once 语义)
- Kafka Streams
- KSQL(流式 SQL)
- 延迟队列实现
- 死信队列(DLQ)
源码底层
- Producer 发送流程
- Consumer 拉取流程
- Rebalance 机制
- Controller 选举
Rebalance机制
- 分区分配策略(Range / RoundRobin / Sticky)
- Rebalance 为什么会卡顿?
- 如何优化 Rebalance?
运维与调优
部署模式
- 单节点 / 集群
- ZooKeeper(旧) vs KRaft(新)
常见调优点
- 分区数怎么设计?
- 副本数怎么设置?
- 磁盘 vs 网络瓶颈
- 消费堆积如何处理?
项目实践
项目1:日志收集系统
- Nginx → Kafka → ES
- 技术点:
- 高吞吐
- 批量发送
- 数据分区设计
项目2:订单异步处理系统
- 下单 → Kafka → 库存 / 支付 / 通知
- 技术点:
- 解耦
- 消费失败重试
- 幂等设计
项目3:实时数据分析系统
- Kafka → Flink → ClickHouse
- 技术点:
- 流式计算
- 实时指标
其他
- 亿级流量日志系统怎么设计?
- Kafka 如何做削峰填谷?
- 如何避免消息积压?
- Kafka 和数据库如何保证一致性?
Kafak进阶
网络协议模型
- Kafka 自定义二进制协议(不是 HTTP)
- 请求类型(Produce / Fetch / Metadata)
- 网络模型(NIO / Selector)
- 长连接 + 多路复用
直接决定:
- 延迟为什么低
- 为什么能支撑百万 QPS
- Producer 为什么能 batch
时间轮(Timing Wheel)机制
应用场景
- 延迟操作
- 请求超时管理
为什么重要?
👉 Kafka 的很多“定时行为”不是简单 Timer,而是高性能时间轮
Controller & 集群元数据(KRaft)
必补内容
- Controller 是什么
- Leader 选举机制
- 元数据存储方式对比(ZK vs KRaft)
KRaft(重点)
- 基于 Raft 协议
- 去 ZooKeeper
- 元数据日志化
Rebalance
深入点
- Rebalance 触发条件
- Stop-The-World 问题
- Cooperative Rebalance(新机制)
实战问题
- 为什么消费会“突然卡死”?
- 为什么 CPU 飙升?
- 为什么重复消费?
数据语义(Exactly Once )
三种语义
- At Most Once
- At Least Once
- Exactly Once(重点)
背压(Backpressure)机制
- 消费跟不上怎么办?
- 如何限流?
- Producer 如何感知压力?
相关参数
- linger.ms
- batch.size
- fetch.min.bytes
日志压缩(Log Compaction)
作用
- 保留 Key 最新值
- 做状态存储
应用场景
- 用户画像
- 配置中心
- CDC(变更数据捕获)
必备组件
- Kafka Connect(数据集成神器)
- Schema Registry(Avro / Protobuf)
- Debezium(CDC)
8大板块
- 数据模型(Topic / Partition)
- 存储引擎(Log + Segment)
- 网络模型(NIO + 协议)
- 副本机制(ISR + Leader)
- 一致性(ACK / 事务 / EOS)
- 调度机制(Rebalance / 时间轮)
- 集群控制(Controller / KRaft)
- 生态系统(Connect / Streams)